xue
学
tu
途

Hello,又是一个分享的日子,上期博主介绍了BP神经网络回归---房价预测,想把整体的BP神经网络的应用都掌握的小伙伴,可以去翻一下。当然啦,还没了解原理的小伙伴也可以去看一下深度学习开端---BP神经网络。
这期,博主给大家分享如何用BP神经网络对招聘数据进行分类,从而训练出一个可以分类招聘信息的神经网络模型。
下面就开始我们新的征程。
自然语言处理
文本表示

计算机是无法直接处理文本信息的,所以,在我们构建神经网络之前,要对文本进行一定的处理。
相信大家对独热编码(one-hot encode)应该不陌生了,虽说它能把所有文本用数字表示出来,但是表示文本的矩阵会非常的稀疏,极大得浪费了空间,而且这样一个矩阵放入神经网络训练也会耗费相当多的时间。
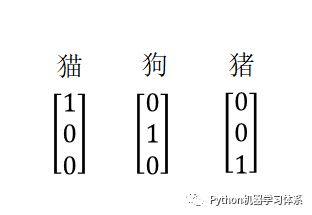
独热编码示意图
为此,有些聪明的小伙伴提出了词向量模型(Word2Vec)。词向量模型是一种将词的语义映射到向量空间的技术,说白了就是用向量来表示词,但是会比用独热编码用的空间小,而且词与词之间可以通过计算余弦相似度来看两个词的语义是否相近。下面给大家展示Word2Vec的示意图。
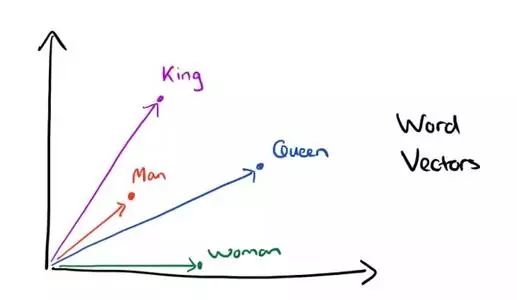
图片来源于网络
目前Word2Vec技术有好几种:CBOW、Skip-gram和GloVe,这里限于篇幅,且我们的实验用的词向量模型是Skip-gram,这里只介绍Skip-gram模型。博主会在后期更新一篇新的推文介绍另外两个的具体细节,它们总体的原理和Skip-gram大致相同。
Skip-gram
Skip-gram是输入一个词,预测该词上下文的模型。
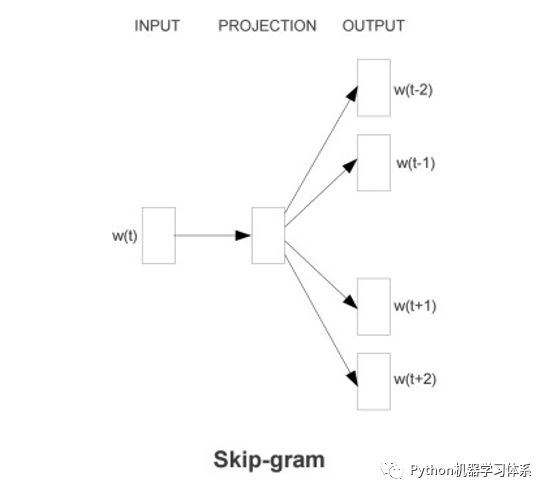
图片来源于网络
Skip-gram的具体训练过程如下,蓝色代表输入的词,图中的框框代表滑动窗口,用来截取蓝色词的上下文,然后形成训练标本(Training Samples),这样我们就得到了{输入和输出},放入{输入层-隐藏层-输出层}的神经网络训练,我们就能得到Skip-gram模型。因为神经网络不能直接处理文本,因此所有的词都用one-hot encode表示。

Skip-gram训练过程
图片来源于网络
Skip-gram的神经网络结构如下,隐藏层有300个神经元无激励函数,输出层用softmax激励函数,通过我们提取的词与其相应的上下文去训练,得到相应的模型。通过Softmax激励函数,输出层每个神经元输出的是概率,加起来等于1。
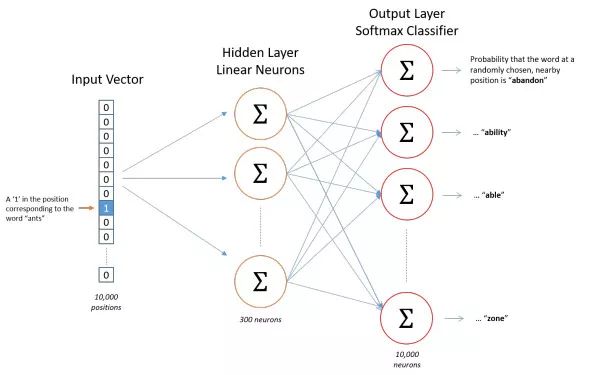
Skip-gram网络结构
图片来源于网络
但输出层并不是我们关心的,我们去掉模型的输出层,才是我们想要的词向量模型,我们通过隐藏层的权重来表示我们的词。
现在假设我们有10000个词,每个词用one-hot encode编码,每个词大小就是1*10000,现在我们想用300个特征去表示一个词,那么隐藏层的输入是10000,输出是300(即300个神经元),因此它的权值矩阵大小为10000 * 300。那么我们的词向量模型本质上就变成了矩阵相乘。
好了,讲到这,大家已经把词向量的原理了解清楚了,而且值得高兴的是,Keras自带了词向量层embedding layer,所以我们只要将文本处理好,就可以灌入这个层中即可,后面的实验博主会给大家细讲如何对文本进行预处理,生成符合embedding layer输入格式的词。
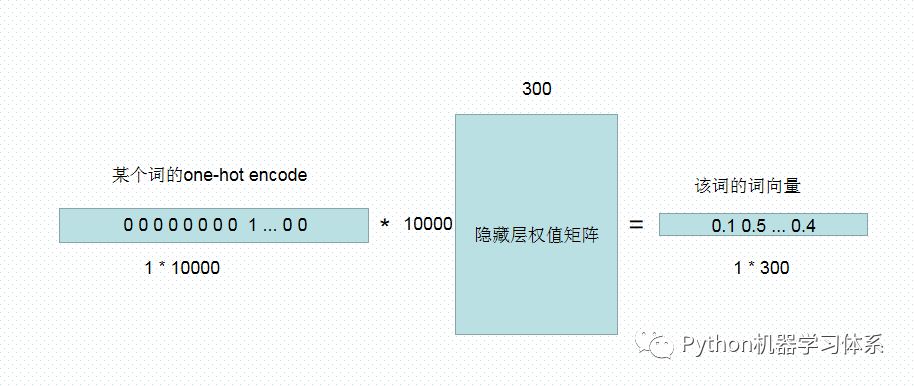
[1*10000] * [10000 * 300] = [1 * 300]
矩阵相乘
中文分词--jieba分词
中文文本处理会比处理英文多一步,中文词与词之间并不是用“空格”分开的,计算机不能处理这么高度抽象的文字,所以我们得通过一个Python库---jieba来将中文文本进行分词,然后用“空格”将词分开,形成类似英文那样的文本,方便计算机处理。

jieba分词示例图
# 安装指令pip install jieba实验
实验环境
Anaconda Python 3.7
Jupyter Notebook
Keras
开发环境安装在之前的推文中已经介绍,还没安装的小伙伴可以翻一下。
Python开发环境---Windows与服务器篇
Python深度学习开发环境---Keras
招聘数据集
提取码:38wa
https://pan.baidu.com/s/1t7MbjxIYN7afW9EyHeOuNQ
实验流程
加载数据
数据上标签
中文分词
提取文本关键词
建立token字典
使用token字典将“文字”转化为“数字列表”
截长补短让所有“数字列表”长度都是50 # 保证每个文本都是同样的长度,避免不必要的错误。
Embedding层将“数字列表”转化为"向量列表"
将向量列表送入深度学习模型进行训练
保存模型与模型可视化
模型的预测功能
训练过程可视化
代码
核心代码
batch_size = 256epochs = 5model = Sequential()# 词嵌入层model.add(Embedding(output_dim = 32, # 词向量的维度 input_dim = 2000, # 字典大小 input_length = 50 # 每个数字列表的长度 ) )model.add(Dropout(0.2)) model.add(Flatten()) # 平铺model.add(Dense(units = 256, activation = "relu"))model.add(Dropout(0.25))model.add(Dense(units = 10, activation = "softmax"))print(model.summary()) # 打印模型# CPU版本model.compile(loss = "sparse_categorical_crossentropy", # 多分类损失函数 optimizer = "adam", metrics = ["accuracy"] )history = model.fit( x_train, y_train, batch_size = batch_size, epochs = epochs, verbose = 2, validation_split = 0.2 # 训练集的20%用作验证集)参数
Dense: 全连接层。
Dropout: 以一定概率放弃两层之间的一些神经元链接,防止过拟合,可以加在网络层与层之间。
optimizer: 优化器,梯度下降的优化方法
这些都在之前的推文中有所介绍,小伙伴们可以去翻阅一下。
码前须知---TensorFlow超参数的设置
activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层。
loss: 拟合损失方法,这里用到了多分类损失函数交叉熵
如果你的label 是 数字编码 ,用 sparse_categorical_crossentropy,
如果你的 label是 one-hot 编码,用 categorical_crossentropy
keras还有别的误差函数,在后续的推文会一一介绍。
epochs 与 batch_size:前者是迭代次数,后者是用来更新梯度的批数据的大小,iteration = epochs / batch_size, 也就是完成一个epoch需要跑多少个batch。这这两个参数可以用控制变量法来调参,控制一个参数,调另外一个,看损失曲线的变化。
小伙伴们可以去keras官网查看更多的参数含义与用途,博主也会在后续的课程中通过实验的方法将这些参数涉及进来,让大家的知识点串联起来。
Keras官网
https://keras.io/
Git链接
代码
https://github.com/ChileWang0228/DeepLearningTutorial/blob/master/MLP/MLP_Text.ipynb
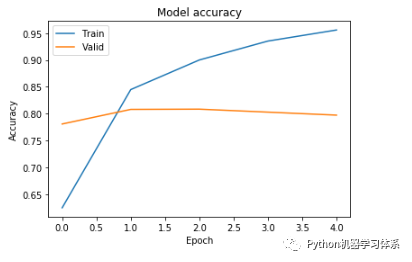
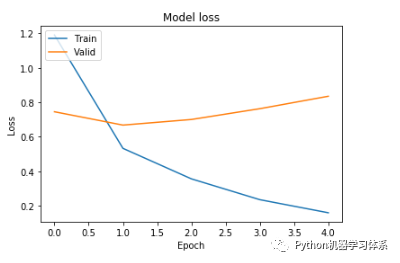
训练结果
训练过程
网络结构
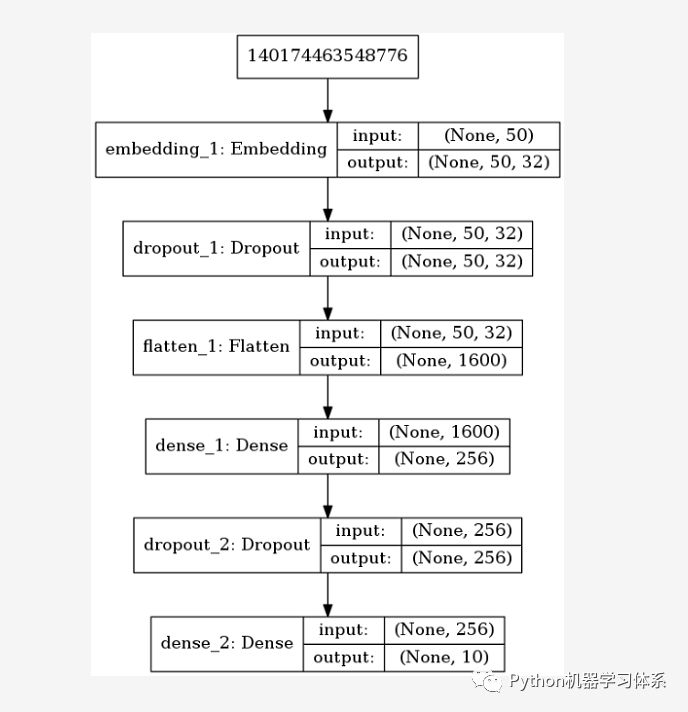
结果分析
在迭代了1个epochs之后,验证集的损失loss和acc,趋于平稳,这时,我们得到的模型已经是最优的了。所以讲epoch设置为1即可。
代码实践视频
视频卡顿?bilibili值得拥有~(っ•̀ω•́)っ✎⁾⁾ 我爱学习
https://www.bilibili.com/video/av56109416/
总结
好了,到这里,我们就已经将BP神经网络文本分类的知识点讲完了。大家在掌握了整个流程之后,就可以在博主的代码上修修补补,训练自己的神经网络来做文本分类任务了。
下一期,博主就带领大家用CNN卷积神经网络来做文本分类,敬请期待吧~
留言

博主刚弄的一个留言功能,欢迎各位小伙伴踊跃留言~